CarpetCode
home page
Documentation
Introduction (PDF, 170 kB)
First Steps (PDF, 90 kB)
Scheduling (PDF, 160 kB)
Grid Structure (PDF, 120 kB)
Internals (PDF, 130 kB)
Other Carpets
Mailing Lists
Subscribe
List Archive
CVS messages
darcs/git messages
Development
Download
Bug Reports
Contributors
Visualisation
Tools
Mailing List
Results
Publications
Related
Cactus
LSU Relativity Group
numrel@CCT
numrel@aei
Whisky
Taka
parca
Carpet Users
AEI Potsdam
University of Arizona
Jena
KISTI
LSU
Parma
Penn State
RIT
SISSA
Southampton
TAT/CPT
Torino
UIUC
UNAM
WashU
Feedback
Send email
Carpet is an adaptive mesh refinement driver for the Cactus Framework. Cactus is a software framework for solving time-dependent partial differential equations on block-structured grids, and Carpet acts as driver layer providing adaptive mesh refinement, multi-patch capability, as well as parallelisation and efficient I/O.
Carpet was created in 2001 by Erik Schnetter at the TAT (Theoretische Astrophysik Tübingen) and subsequently brought into production use by Erik Schnetter, Scott Hawley, and Ian Hawke at the AEI (Max-Planck-Institut für Gravitationsphysik, Albert-Einstein-Institut). Carpet is currently maintained at the CCT (Center for Computation & Technology) at LSU. These pages describe Carpet and its current development.
News
|
March 29, 2008: We have benchmarked McLachlan, a new BSSN-type vacuum Einstein code, using Carpet for unigrid and AMR calculations. We compare several current large machines: Franklin (NERSC), Queen Bee (LONI), and Ranger (TACC). These machines have different architectures and interconnects. |
|
|


|
March 1, 2008: Carpet has a logo! This logo is a Sierpiński carpet, which is a fractal pattern with a Hausdorff dimension of 1.89279. |
|
March 1, 2008: We have improved the development version
of Carpet significantly:
The data structures and algorithms storing and handling the communication schedule are much more efficient on large numbers (several hundred or more) processors. This makes Carpet scale to more than 8,000 cores.
The interface for defining and making dynamic changes to grid hierarchies is simpler, and buffer zones are handled in a cleaner manner. This makes it easier to write user code which defines or updates the grid hierarchy, and reduces the chance of inconsistencies therein.
During checkpointing and recovery, the grid structure is saved and restored by default. This avoids accidental changes upon recovery.
The efficiency of I/O has been increased, especially for HDF5 based binary I/O. It is possible to combine several variables into one file to reduce the number of output files.
A new thorn LoopControl offers iterators over grid points, implemented as C-style macros. These iterators allow additional important loop-level optimisations, such as loop tiling or OpenMP parallelisation. Efficient cache handling and hybrid communication models have a large potential for performance improvements on current and future architectures.
More details can be found here. These improvements are largely due to Erik Schnetter (LSU), Thomas Radke (AEI), and Christian D. Ott (UA). Special thanks go to Christian Reisswig and Luca Baiotti.
March 1, 2008: The development version of Carpet is now maintained using git instead of darcs. Git offers a very similar set of features to darcs, most importantly supporting decentralised development. Git has a much larger user community than darcs, and we hope that this makes it easier to use. The download instructions contain details on using git to obtain Carpet, and point to further information. (The darcs repository for the development version will not see any further changes.)
March 1, 2008: The repository for the development version of Carpet moved today to a new server. The stable versions of Carpet continue to be served from the old server for the time being. We plan to move all of carpetcode.org to this new server in the future. The new server is a courtesy of Christian D. Ott.
|
January 14, 2008: Carpet's communication infrastructure has been improved significantly, making Carpet scale to at least 4,000 processors, including mesh refinement. Using "friendly user time" on Ranger, the new 60,000 core TeraGrid supercomputer at TACC, we measured the benchmark results below for a numerical relativity kernel solving the BSSN equations. These benchmarks emply a hybrid communication scheme combining MPI and OpenMP, using the shared memory capabilities of Ranger's nodes to reduce the memory overhead of parallelisation. We are grateful for the help we received from Ranger's support team. The graph below shows weak scaling tests for both unigrid and mesh refinement benchmarks. The problem size per core was kept fixed, and there were 4 OpenMP threads per MPI process, with 1 MPI process per socket. The benchmark was also run with the PUGH driver for comparison for certain core counts. As the graphs show, this benchmark scales near perfectly for unigrid, and has only small variations in run time for nine levels of mesh refinement. |
|

October 3, 2007: Carpet's timing infrastructure has been extended to automatically measure both time spent computing and time spent in I/O. The performance of large simulations depends not only on the computational efficiency and communication latency, but also on the throughput to file servers. These new statistics give a real-time overview and can point out performance problems. The statistics are collected in the existing Carpet::timing variables.
August 30, 2007: So far this year, ten of the
publications from three research groups examining the dynamics
of binary black hole systems are based on simulations performed
with Cactus and Carpet:
Astrophys. J. 661, 430-436 (2007)
(arXiv:gr-qc/0701143)
Phys. Rev. Lett. 99, 041102 (2007)
(arXiv:gr-qc/0701163)
Astrophys. J. 659, L5-L8 (2007)
(arXiv:gr-qc/0701164)
Phys. Rev. Lett. 98, 231102 (2007)
(arXiv:gr-qc/0702133)
Class. Quantum Grav. 24, 3911-3918 (2007)
(arXiv:gr-qc/0701038)
arXiv:0705.3829 [gr-qc]
arXiv:0706.2541 [gr-qc]
arXiv:0707.2559 [gr-qc]
arXiv:0708.3999 [gr-qc]
arXiv:0708.4048 [gr-qc]
These publications mainly examine the spin dynamics and the
gravitational wave recoil in BBH systems. Since not all
research groups use Cactus and Carpet, this represents only part
of the published work on this subject.
|
August 26, 2007: In experiments with hybrid communication schemes combining MPI and OpenMP, we found a 20% speed improvement when using a single node of Abe at NCSA, and a substantial scaling improvement when using 1024 and more CPUs. (Abe has 8 CPUs per node.) These experiments included cache optimisations when traversing the 3D arrays. The tests were performed with a modified version of the Cactus WaveToy example application without using I/O or analysis methods. |
|

August 15, 2007: We are happy to hear that our proposal ALPACA: Cactus tools for Application Level Profiling And Correctness Analysis will be funded by NSF's SDCI programme for three years. The ALPACA project is aiming at developing complex, collaborative scientific applications, appropriate for highly scalable hardware architectures, providing fault tolerance, advanced debugging, and transparency against new developments in communication, programming, and execution models. Such tools are especially rare at the application level, where they are most critically needed.
July 31, 2007: We are happy to hear that our proposal XiRel: Cyberinfrastructure for Numerical Relativity will be funded by NSF's PIF programme for three years. XiRel is collaborative proposal by LSU, PSU, and UTB (now RIT). The central goal of XiRel is the development of a highly scalable, efficient, and accurate adaptive mesh refinement layer based on the current Carpet driver, which will be fully integrated and supported in Cactus and optimised for numerical relativity.
Documentation
We have accumulated a few pieces of documentation:
- An introduction (PDF, 210 kB) to Carpet, as well as a guide to the first steps for using it. Everybody should have read this. (This is the same as the Arrangement Guide from the Carpet sources.)
- Ulrich Sperhake wrote a tutorial outlining the first steps (PDF, 130 kB) that one has to take to install Carpet and run an example application.
- An explanation of the internal workings (PDF, 120 kB) of Carpet. You should read this if you want to modify Carpet.
- An explanation of how scheduling works (PDF, 120 kB) in (PUGH and) Carpet. This may be useful for setting up mixtures of local and global operations.
- The individual Thorn Guides of Carpet. They are available with the source code. They give details about the thorns' APIs and user interfaces.
- Thanks to Doxygen, we now have an overview over all the routines and data structures in Carpet. Most individual Doxygen tags are still missing, but the extracted documentation is already very useful. (The online documentation might not always be up to date; in case of doubt, extract the documentation yourself.)
Interacting with the developers
Most discussions about Carpet, i.e. user questions, feature requests, and bug reports, are held on the Carpet developers' mailing list developers@lists.carpetcode.org. You can subscribe and unsubscribe from our list management web page. You will also find the mailing list archive there. We thank Daniel Kobras for managing the mailing list server.
We have started to use Bugzilla to keep track of requested features or reported bugs in Carpet. You can submit or comment on issues from our Bugzilla pages once you have created an account there. The old list of missing features have not yet been moved over to Bugzilla.
Pretty pictures
Here are some pretty pictures of simulations that were performed with Carpet:
|
|
Cut through a binary black hole system. Height field of the lapse function (approximately the time dilatation) in a binary black hole system calculated from Meudon initial data. The system is cut between the two black holes, so that only one black hole is visible. The white boxes indicate the hierarchy of refinement regions. |
|
A quadrupole wave. Two rotating scalar charges create a quadrupolar wave, mimicking the gravitational wave trail of a binary black hole system. The small bumps and riddles are artifacts caused by the discontinuous charge distribution. To be improved. |
|
|
|
Lapse isosurfaces in a binary black hole system. The same system as above, but the lapse function is rendered as isosurfaces. |
|
A velocity component in a stellar core collapse. The x component of the fluid velocity in a stellar core collapse. This simulation was performed by Christian Ott. |
|
|
|
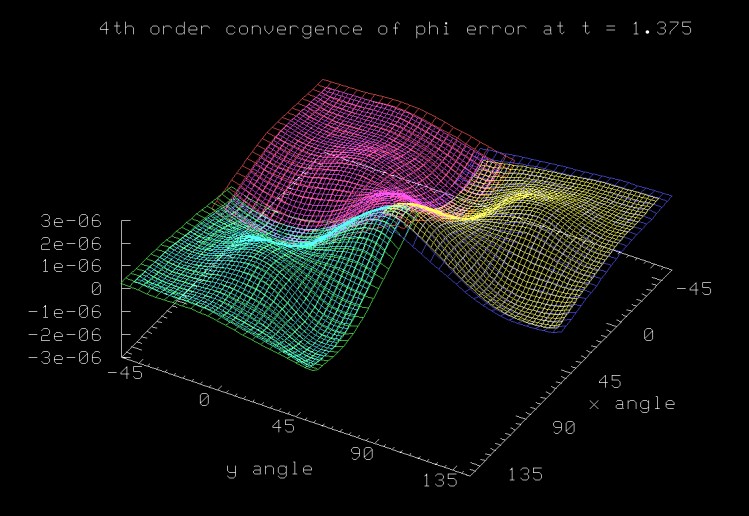
The error in a multipatch numerical simulation of scalar wave propagation in a hollow spherical shell. The coarse- and fine-grid surface show the numerical errors (computed solution - exact solution) computed at two different resolutions, with the low resolution error divided by 16. The fact that the two surfaces overlap nicely shows that the errors scale as the 4th power of the grid resolution. This simulation was performed by Jonathan Thornburg. |
|
The fate of a proto-neutron-star bar-mode deformation. Matter density at z=0 during the transition from an m=2 deformed star to an m=1 deformed one. The light on the right is used to emphasizes the spiral arms which are responsible for a small mass loss. This simulation was performed by Gian Mario Manca. |

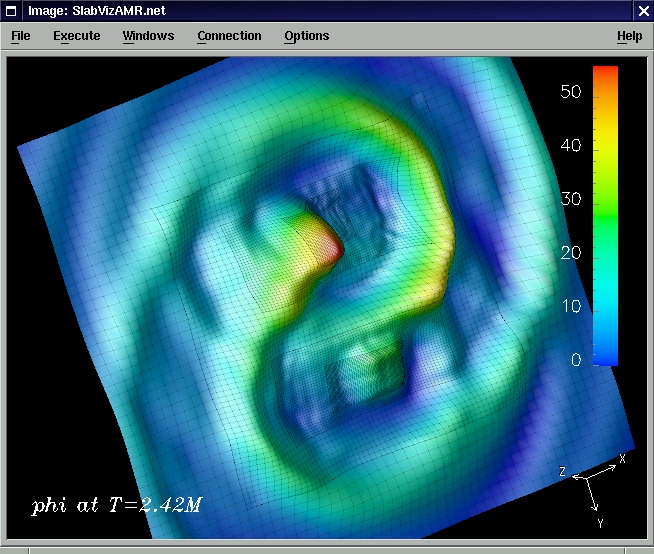



Moving pictures: We can show a movie (animated gif, 3.3 MB) of a scalar wave equation with adaptive mesh refinement. The refinement criterion is a very simplistic local truncation error estimate. We also have a movie (animated gif, 730 kB) of a moving refinement region tracking a black hole.
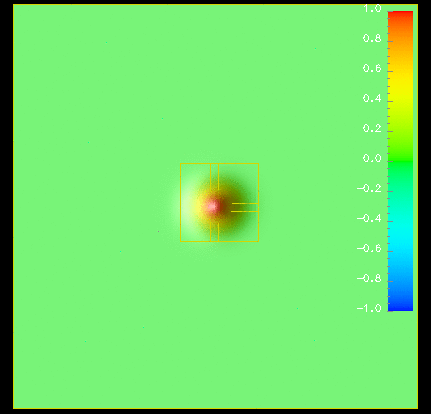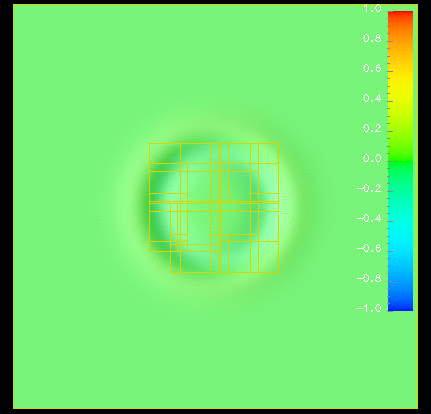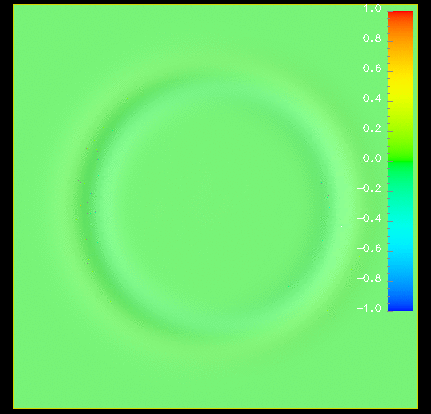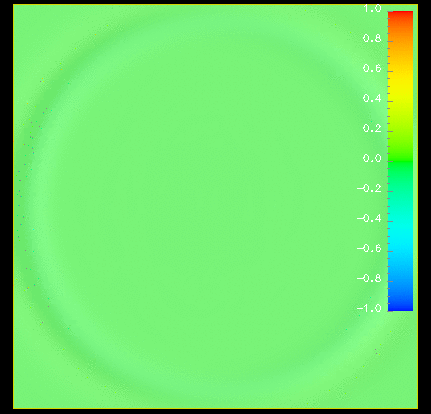{kind=link}
{kind=link}
Making sense of results
Three-dimensional time-dependent simulation results are difficult enough to interpret when the grid is uniform. With mesh refinement, the sheer amount of available data makes it necessary to use professional tools to examine the data. This is not only the case for "big physics runs", where one (should) know in advance what to expect, but especially during development, where things do not always go as planned. Christian Reisswig was kind enough to write a database plugin for the visualisation tool VisIt. There is also an import module for the visualisation tool OpenDX available, implemented by Thomas Radke.
Related projects
![]()
![]()
![]()
Last modified: Sat Mar 01 2008