CarpetCode
home page
Documentation
Introduction (PDF, 170 kB)
First Steps (PDF, 90 kB)
Scheduling (PDF, 160 kB)
Grid Structure (PDF, 120 kB)
Internals (PDF, 130 kB)
Other Carpets
Mailing Lists
Subscribe
List Archive
CVS messages
darcs/git messages
Development
Download
Bug Reports
Contributors
Visualisation
Tools
Mailing List
Results
Publications
Related
Cactus
LSU Relativity Group
numrel@CCT
numrel@aei
Whisky
Taka
ParCa
Carpet Users
AEI Potsdam
Barcelona
Caltech
Georgia Tech
KISTI
LSU
NASA Goddard
Parma
RIT
SISSA
Southampton
TAT/CPT
Tokyo University
UIUC
UNAM
WashU
YITP
Feedback
Send email
Carpet is an adaptive mesh refinement and multi-patch driver for the Cactus Framework. Cactus is a software framework for solving time-dependent partial differential equations on block-structured grids, and Carpet acts as driver layer providing adaptive mesh refinement, multi-patch capability, as well as parallelisation and efficient I/O.
Carpet was created in 2001 by Erik Schnetter at the TAT (Theoretische Astrophysik Tübingen) and subsequently brought into production use by Erik Schnetter, Scott Hawley, and Ian Hawke at the AEI (Max-Planck-Institut für Gravitationsphysik, Albert-Einstein-Institut). Carpet is currently maintained at the CCT (Center for Computation & Technology) at LSU. These pages describe Carpet and its current development.
News
|
March 30, 2009: We have ported Carpet to the BlueGene/P architecture, using the Surveyor system at the ALCF. The graph to the right shows preliminary performance and scaling results, comparing different compilers and options (gcc, IBM's XL compilers without OpenMP, and IBM's XL compilers with OpenMP, which required reducing the optimisation level). For these benchmarks, the problem size was reduced to about one eighth of the standard size, using 133 grid points per core. The results show that Carpet scales fine up to the size of the total machine (4k cores), but further work on compiler options is required. |
|

|
March 20, 2009: Carpet can now perform performance experiments by artificially increasing the size or the number of MPI messages exchanged between processes. This can help determine whether either the communication bandwidth or the communication latency are a bottleneck of a particular simulation. The figure to the right shows results for the standard McLachlan AMR benchmark run on the Cray XT4 Kraken, using 253 grid points per core. These results indicate that the additional latency from increasing the number of messages has no significant effect, and hence the benchmark is bandwidth limited for this problem size. |
|

|
March 16, 2009: Erik Schnetter and Steve Brandt published a white paper Relativistic Astrophysics on the SiCortex Architecture. This paper expands on a webinar by Erik and Steve that was hosted by SiCortex. The graph at the right shows Carpet's parallel scalability using the McLachlan code with nine levels of AMR for a set of current HPC systems. The results have been rescaled to the architectures' theoretical single-core peak performance. This makes it possible to compare Carpet's scalability on different architectures. (It is not possible to compare the systems' absolute performance in this figure.) |
|

|
November 9, 2008: In the context of the XiRel project, we re-designed Carpet's communication layer to avoid many operations that had a cost of O(N), growing linearly with the number of MPI processes. Such costs are generally not acceptable when running on several thousand cores, and have to be reduced e.g. to O(log N). Carpet now stores the communication schedule (mostly) in a distributed manner, increasing performance and reducing its memory requirement. These improvements are currently being tested; preliminary scaling results are shown in the figure to the right. |
|

June 25, 2008: We are happy to announce the Simulation Factory, a tool to help access remote HPC systems, manage source trees, and submit and control simulations. The Simulation Factory contains a set of abstractions of the tasks which are necessary to set up and successfully finish numerical simulations using the Cactus framework. These abstractions hide tedious low-level management tasks, they capture "best practices" of experienced users, and they create a log trail ensuring repeatable and well-documented scientific results. Using these abstractions, many types of potentially disastrous user errors are avoided, and different supercomputers can be used in a uniform manner.
|
March 29, 2008: We have benchmarked McLachlan, a new BSSN-type vacuum Einstein code, using Carpet for unigrid and AMR calculations. We compare several current large machines: Franklin (NERSC), Queen Bee (LONI), and Ranger (TACC). |
|
|


Documentation
We have accumulated a few pieces of documentation:
- An introduction (PDF, 210 kB) to Carpet, as well as a guide to the first steps for using it. Everybody should have read this. (This is the same as the Arrangement Guide from the Carpet sources.)
- Ulrich Sperhake wrote a tutorial outlining the first steps (PDF, 130 kB) that one has to take to install Carpet and run an example application.
- An explanation of the internal workings (PDF, 120 kB) of Carpet. You should read this if you want to modify Carpet.
- An explanation of how scheduling works (PDF, 120 kB) in (PUGH and) Carpet. This may be useful for setting up mixtures of local and global operations.
- The individual Thorn Guides of Carpet. They are available with the source code. They give details about the thorns' APIs and user interfaces.
- Thanks to Doxygen, we now have an overview over all the routines and data structures in Carpet. Most individual Doxygen tags are still missing, but the extracted documentation is already very useful. (The online documentation might not always be up to date; in case of doubt, extract the documentation yourself.)
Interacting with the developers
Most discussions about Carpet, i.e. user questions, feature requests, and bug reports, are held on the Carpet developers' mailing list developers@lists.carpetcode.org. You can subscribe and unsubscribe from our list management web page. You will also find the mailing list archive there. We thank Daniel Kobras for managing the mailing list server.
We have started to use Bugzilla to keep track of requested features or reported bugs in Carpet. You can submit or comment on issues from our Bugzilla pages once you have created an account there. The old list of missing features have not yet been moved over to Bugzilla.
Pretty pictures
Here are some pretty pictures of simulations that were performed with Carpet:
|
|
Cut through a binary black hole system. Height field of the lapse function (approximately the time dilatation) in a binary black hole system calculated from Meudon initial data. The system is cut between the two black holes, so that only one black hole is visible. The white boxes indicate the hierarchy of refinement regions. |
|
A quadrupole wave. Two rotating scalar charges create a quadrupolar wave, mimicking the gravitational wave trail of a binary black hole system. The small bumps and riddles are artifacts caused by the discontinuous charge distribution. To be improved. |
|
|
|
Lapse isosurfaces in a binary black hole system. The same system as above, but the lapse function is rendered as isosurfaces. |
|
A velocity component in a stellar core collapse. The x component of the fluid velocity in a stellar core collapse. This simulation was performed by Christian Ott. |
|
|
|
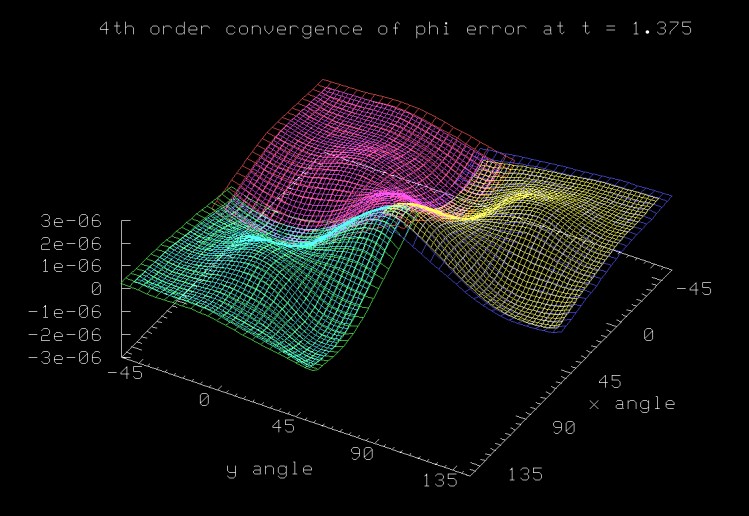
The error in a multipatch numerical simulation of scalar wave propagation in a hollow spherical shell. The coarse- and fine-grid surface show the numerical errors (computed solution - exact solution) computed at two different resolutions, with the low resolution error divided by 16. The fact that the two surfaces overlap nicely shows that the errors scale as the 4th power of the grid resolution. This simulation was performed by Jonathan Thornburg. |
|
The fate of a proto-neutron-star bar-mode deformation. Matter density at z=0 during the transition from an m=2 deformed star to an m=1 deformed one. The light on the right is used to emphasizes the spiral arms which are responsible for a small mass loss. This simulation was performed by Gian Mario Manca. |

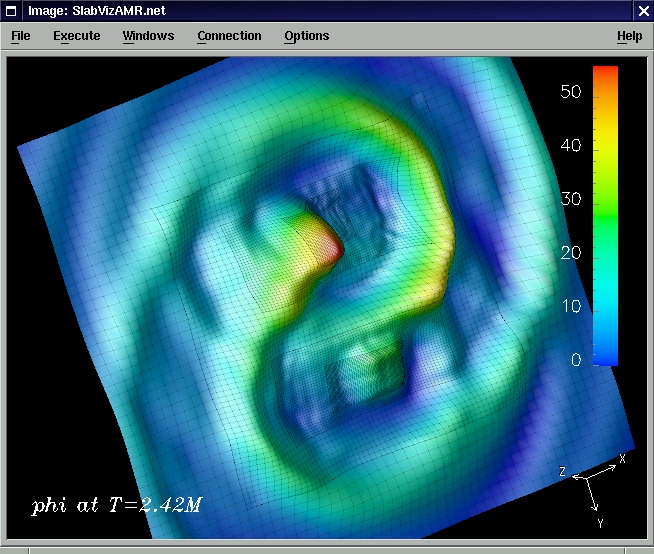



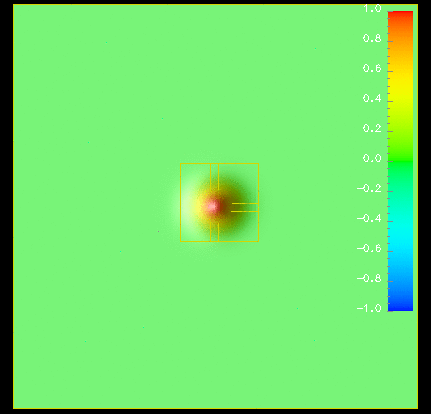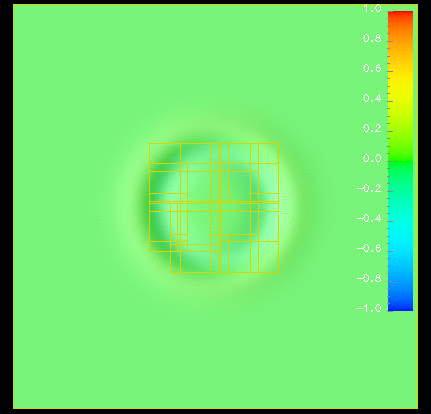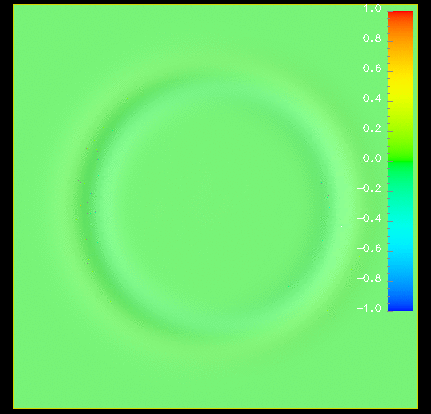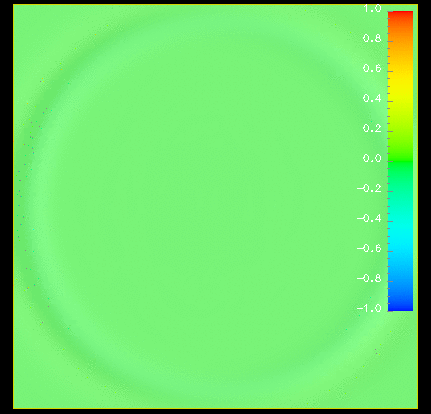
Moving pictures: We can show a movie (animated gif, 3.3 MB) of a scalar wave equation with adaptive mesh refinement. The refinement criterion is a very simplistic local truncation error estimate. We also have a movie (animated gif, 730 kB) of a moving refinement region tracking a black hole.
{kind=link}
{kind=link}
Making sense of results
Three-dimensional time-dependent simulation results are difficult enough to interpret when the grid is uniform. With mesh refinement, the sheer amount of available data makes it necessary to use professional tools to examine the data. This is not only the case for "big physics runs", where one (should) know in advance what to expect, but especially during development, where things do not always go as planned. Christian Reisswig was kind enough to write a database plugin for the visualisation tool VisIt. There is also an import module for the visualisation tool OpenDX available, implemented by Thomas Radke.
Related projects
![]()
![]()
![]()
Last modified: Mon Mar 30 2009